
When training Large Language Models and utilizing machine learning, the significance of precise and efficient data labeling cannot be overstated. High-quality labeled data becomes central as businesses and organizations pivot towards data-centric strategies.
Sense Street uses machine learning to extract nuanced information from complex trader chats. Their models understand a comprehensive array of jargon used across the life cycle of a trade. By adopting Label Studio Enterprise, Sense Street has achieved a 120% increase in annotations per labeler and expanded its team size fourfold. This platform also enabled a 50% growth in their data labeling scope, ensuring more detailed data categorization and enhancing the overall quality of their data annotation efforts.
Label Studio Enterprise’s advanced features, such as overlapping spans, relations, and multi-class classification, played a pivotal role in these improvements. Its customizable interfaces, progress tracking, and quality control mechanisms streamlined Sense Street's operations. The platform's review process and the ability to foster clear communication between annotators and reviewers have been particularly beneficial.
Drawing from the insights of Daria Paczesna, a linguist with Sense Street, here are ten actionable tips to elevate your data labeling processes.
Machine learning is fast-evolving, and starting every annotation from scratch is time-consuming. AI-assisted labeling involves using machine learning algorithms to provide initial labels, acting as a base for human annotators to refine. This combination of machine speed with human expertise ensures accuracy and efficiency.
Clear instructions are essential. Comprehensive guidelines lay down the criteria for labeling, ensuring uniformity. These guidelines serve as a reference point, clearing doubts and ambiguities and providing a roadmap to annotators.
Open communication channels between annotators, reviewers, and project managers ensure continuous learning. Feedback loops help identify challenges, correct real-time errors, and refine processes.
Every domain has its nuances. Domain-specific training equips annotators with the knowledge of industry-specific terms and practices, ensuring they grasp the subtleties of the data they are labeling.
An overload can lead to mistakes, stress, and burnout. Ensuring annotators have a balanced workload ensures they give their best to each task without compromising quality.
Repetitive tasks can lead to fatigue and errors. By rotating tasks, you keep the job interesting and the mind fresh, ensuring consistent quality and engagement.
Customizing the interface tailors the annotator's workspace to their needs, streamlining the process. Whether it's language-based tabs for multilingual data or expertise-based tabs for specialized data, customizations ensure efficiency.
Filters let annotators focus on specific subsets of data. By narrowing down data based on particular criteria, annotators can work more efficiently and with higher precision.
A dynamic environment where annotators can comment, discuss challenges, and seek clarity ensures collective problem-solving and maintains high-quality data.
Explanation: Multiple perspectives ensure comprehensive data understanding. When several annotators review the same data, it brings varied interpretations, providing a well-rounded view and higher accuracy.
In conclusion, data labeling is a harmonious blend of technology, human expertise, and strategic planning. By integrating these ten tips, organizations can set the stage for a data labeling process that's both efficient and precise, laying the groundwork for successful AI and machine learning outcomes.

These five tips for using Label Studio's API and SDK demonstrate these tools' powerful capabilities and flexibility for managing data labeling projects. From efficient project creation and task imports to advanced configurations and bulk data exports, Label Studio provides a comprehensive and streamlined approach suitable for beginners and advanced users.

Chief Scientist of AI
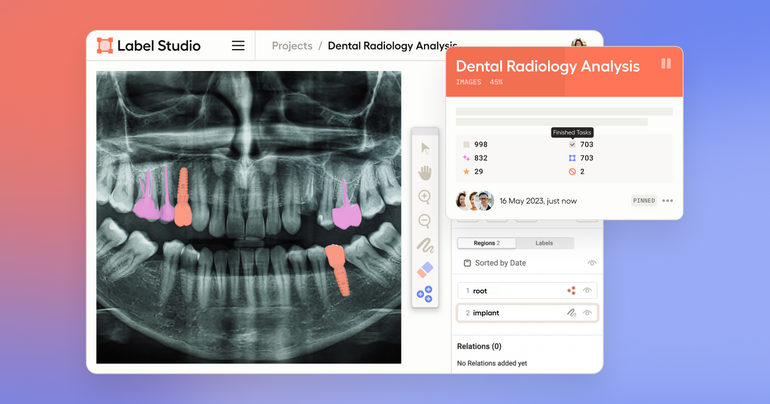
From precise disease diagnoses to personalized treatment plans, accurately labeled data profoundly impacts healthcare. This guide explores the fundamentals of medical data labeling, its applications, and its evolution through AI.

The realm of data labeling is undergoing significant transformations, reflecting the dynamic nature of the tech industry. Here are some of the most notable trends and their implications.