Customer Story
How To Build Your Annotation Team for the Data Design Lifecycle
In Conversation With

Aaron Schliem
Senior Solutions Architect
Customer Story
In Conversation With
Senior Solutions Architect
During a recent webinar with The Label Studio, Aaron Schliem, the Senior Solutions Architect at Welocalize, shared his expertise on the data design lifecycle that he has implemented at Welocalize.
From identifying the problem you want to solve with data to developing a robust data pipeline, Schliem provided valuable insights on how to build an effective annotation team. In this article, we'll delve deeper into Schliem's discussion, breaking down his key points to help you gain a better understanding of the data design lifecycle at Welocalize and how to make the most of your annotation team within this context.

A comprehensive understanding of the entire data design lifecycle is the cornerstone of building a truly successful data pipeline, instead of solely fixating on the data.
According to Schliem, it's crucial to first identify the business problem or target you're solutioning for. Think: what business problem are you trying to solve? This helps ensure the data remains on track and relevant to the desired outcome. "If we don't know what we're solutioning for, it's really easy to get off target with the data," explains Schliem.
Once you've identified the target, it's time to focus on data design.
Being specific and clear about the shape of the data ensures the data labeling experience is designed correctly and enables proper workforce training and documentation. This, in turn, equips your data scientists with a better understanding of the data they're ingesting, helping them develop informed hypotheses about how that data will affect their models.
The final piece of the puzzle is data annotation. Although it may be tempting to jump straight to this step, you should take into consideration the unique challenges of annotation, especially when working at scale or across multiple languages.
For example, if you're localizing across multiple languages, you'll need to ensure your annotation team is skilled in data analysis and has local and domain-specific knowledge to label the data accurately.
Schliem also emphasizes data annotation is not just about getting the work done. There are other factors to consider, such as consistency and accuracy. For instance, if you're annotating images for a machine learning algorithm, you'll have to ensure the annotations are consistent across all images. This will help the algorithm to learn more effectively and produce better results.
In a nutshell, you have to be aligned with the three stages of the data design lifecycle. And then accordingly assemble annotators who have the required skills and expertise to execute each stage of the process.

The solutioning phase of the data design lifecycle is about gaining a clear understanding of the business problem you're trying to solve.
Models and labeled data are not created for their own sake, but to solve specific business problems. So, it's important to determine what those problems are and align them with your company's strategic objectives and product vision. This ensures that the work you do is ultimately solving a problem rather than just generating results.
In addition, consider the availability and quality of existing data. It's worth exploring whether you already have the necessary data or raw material that can be labeled or annotated. And if not, you may need to collect data from scratch, or clean up the available data before loading it into your model.
This step is crucial as the quality of the labeled data directly affects the efficiency of the entire data design lifecycle.
Also, think about the high-level flow of data between different systems. More so, when you're trying to reduce the amount of human work required to complete the entire cycle, from launch to retraining and testing the model.
To ensure a successful solutioning phase, Schliem recommends involving certain key players from the beginning. This includes your product manager, who will provide valuable insight into where the product is headed and how it'll meet your business objectives. Similarly, your marketing managers can help you understand how to use the enhancements you make to your product to sell more or open up new markets.
In addition to these key players, a Solutions Architect can be incredibly helpful in this process. Their expertise in thinking through business problems and translating them into technical initiatives that can deliver perspective is invaluable. And of course, your data scientists and ML Ops team can be responsible for running experiments and feeding data into the model.
By bringing these key individuals together, you can streamline your data flow process and ensure your models are as effective as possible. This will also ensure the work being done aligns with your organization's business objectives and ultimately solves the problem at hand.
Once you've figured out what the overall solution should look like, Schliem emphasizes the importance of considering the task and data design before proceeding to annotation to ensure your project's success.
"In order to avoid potential headaches in the data annotation process, you need to have a well-defined understanding of your dataset design and how you plan to structure the task for your annotators. Failing to do so may result in unforeseen issues that could hinder your progress and cause unnecessary frustration," he advises.
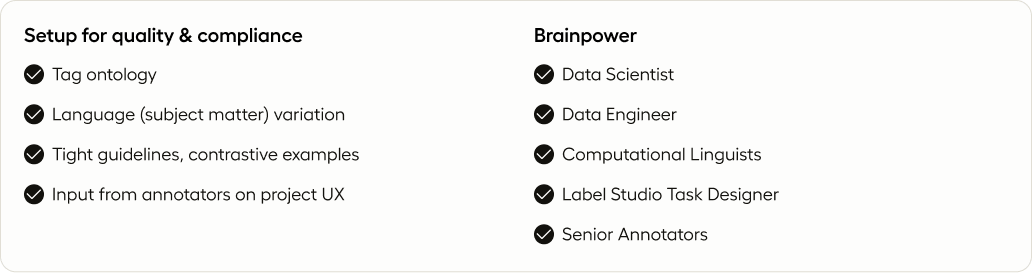
The first step here is determining your tagging ontology.
This involves considering every possible edge case and anticipating how annotators may misunderstand or break your rules. It's your responsibility as the designer to carefully consider all these factors, especially when dealing with variations in language or culture that require different data collection guidelines.
To avoid inconsistency and maximize the accuracy of your data, clear and unambiguous guidelines are essential. Providing contrastive examples is a highly effective technique in achieving this. By presenting both correct and incorrect examples, you can help your annotators understand exactly how tags should be applied. The more examples you provide, the greater the likelihood that your data annotation team will comprehend your goals and consistently apply the labels accordingly.
Next, you need to think about the user experience (UX) of the annotation process.
This means creating an interface that's easy to use and intuitive for annotators, thereby saving you and your team from potential headaches down the line.
To ensure the UX is on point, Schliem recommends involving the right people in the conversation. He explains, "It's easy for a small group to come up with assumptions about how the annotators will experience the interface. But to get a more accurate perspective, it's best to involve the full team, including senior annotators, data scientists, data engineers, and even subject matter experts like computational linguists."
...to get a more accurate perspective, it's best to involve the full team, including senior annotators, data scientists, data engineers, and even subject matter experts like computational linguists.
Aaron Schliem
Senior Solutions Architect
Think about it: designing a dataset and annotation tasks involves collaboration and communication across a range of stakeholders. By bringing together people with a variety of skills and perspectives, you can create a dataset that meets everyone's needs and ensures the best possible results.
If you're designing a task in Label Studio, for example, you can involve your entire team. Start with your Label Studio Test designer who sets up the projects, and then bring in your senior annotators, who have firsthand experience with the actual work involved. If you have a small team, even if it's just three people, they should be a part of the conversation because they can give valuable feedback on the ergonomics of the interface and suggest ways to optimize the process for speed and accuracy.
Remember, collaboration is key when setting up the UX.
You can involve data scientists to ensure the shape of the data enables them to get the result they need. Data engineers are also important because they will be transforming the dataset and can help design the task and data structure for easy ingestion.
You may also need computational linguists or subject matter experts to think about the data effectively and apply their own expertise to data thinking. These people bridge the gap between the data structure and how it's applied to problem solving. They understand how to think about data effectively and can help structure the dataset for optimal results.

When it comes to scaling your data annotation pipeline, there are several important factors to consider.
According to Schliem, the first step is to qualify your workers by determining who will be effective at the task. Aptitude testing is highly recommended, but it doesn't necessarily mean doing the exact task. Your team should have basic aptitudes to ensure they are successful at the job. For example, if the job is to annotate an audio file and ensure the timestamps on the wave file stays within 10 milliseconds, your data annotation team should have a high level of attention to detail.
Another key consideration is trade-offs and demographics. There is no such thing as a perfect annotator. Some people have more subject matter knowledge, while others are more effective at the mechanics of applying tags. So, you have to make trade-offs.
For instance, if you need workers to understand chat language, you may need to look at younger workers who are more likely to be familiar with current texting language. Older workers may not know how that texting language works. In making trade-offs, you may decide you need workers with less experience but who know more about specific subject matter.
It's also important to consider the life experiences of the workers you hire and make sure they reflect the specificity or variation you need in the data. Humans are likely to reflect themselves and their life experiences in the data they're providing to you, so think about that before you set them loose on the data.
When working at scale, you must also take economics into account.
This means understanding the amount of effort required to perform tasks and determining a reasonable throughput, whether you're using salaried employees or outsourcing to gig workers. It's essential to provide fair compensation while also ensuring that workers neither underthink nor overthink tasks. Rushing through tasks can lead to errors, while overthinking can be a common issue in linguistics and can lead to wasted time.
To overcome this issue, calculate the level of effort required and ensure your workers understand it. For instance, if a task only takes 30 seconds, there's no need for someone to spend 15 minutes on research. Conversely, for other tasks, you may need a worker's gut reaction. So, determine the level of effort needed for each task, communicate it to your team, and encourage them to use their best judgment. This approach will help ensure that tasks are completed efficiently and effectively.Another crucial aspect to ensure when managing pipelines or workforce is getting engagement from workers.
The annotation process can become monotonous, so think about what can motivate your team to do a good job consistently. "There is some real merit to thinking about human's competitive spirit, and people's need to be recognized and to achieve and playing on that when you're trying to get engagement from workers," notes Schliem.
There is some real merit to thinking about human's competitive spirit, and people's need to be recognized and to achieve and playing on that when you're trying to get engagement from workers.
Aaron Schliem
Senior Solutions Architect
Consider implementing a badging system or providing incentives for workers who meet specific targets to ensure high-quality and timely completion of data annotation tasks. But, as you set up your system, think about these things carefully because it's much worse to find yourself in a poorly performing annotation pipeline and then try to determine how to get engagement. It's much better to plan for engagement from the start, rather than responding to low engagement.
Schliem also stresses on the importance of thinking through the administrative pieces of managing a pipeline of workers. "Setting clear expectations for workers upfront, including guidelines, training materials, and incentives for good work is crucial. But to ensure the quality of your data, it's equally crucial to plan for handling bad data and off-boarding workers," he says.
Focus on understanding what constitutes bad data, how to identify it, and what action to take when it occurs. This will save you from accumulating poor quality data that could ultimately undermine your entire project.
To handle bad data, you'll have to identify poor performance over time and have a plan for addressing it. For example, you can implement a model that re-trains workers when specific patterns are observed, or you can remove them automatically from the system after a certain number of failures.
It's critical to be tight on this plan because failing to remove workers in the moment of discovery can result in accumulating bad data that's difficult to fix later. Although some degree of bad data may be acceptable in collections, minimizing it is always the goal.
Another important consideration is payment mechanics, particularly for crowd workers or freelance workers. Think about how you can swiftly deliver payment rewards. Workers expect to be promptly rewarded for their hard work, so proactive planning for payment delivery can enhance worker engagement and prevent any potential delays or confusion.
When putting together a team to manage these administrative tasks, Schliem suggests including a community manager who can handle worker engagement, onboarding, training, and communication. Additionally, the annotation workforce responsible for managing the community should be involved, along with the task designer to understand project evolution and iterate on future task design.
Data engineers can assist in identifying and resolving any issues with bad data, while computational linguists or subject matter specialists can help determine the right worker profile based on language, culture, or other specialty subjects. Their input can inform decisions about setting up your system to optimize worker performance and overall project success.
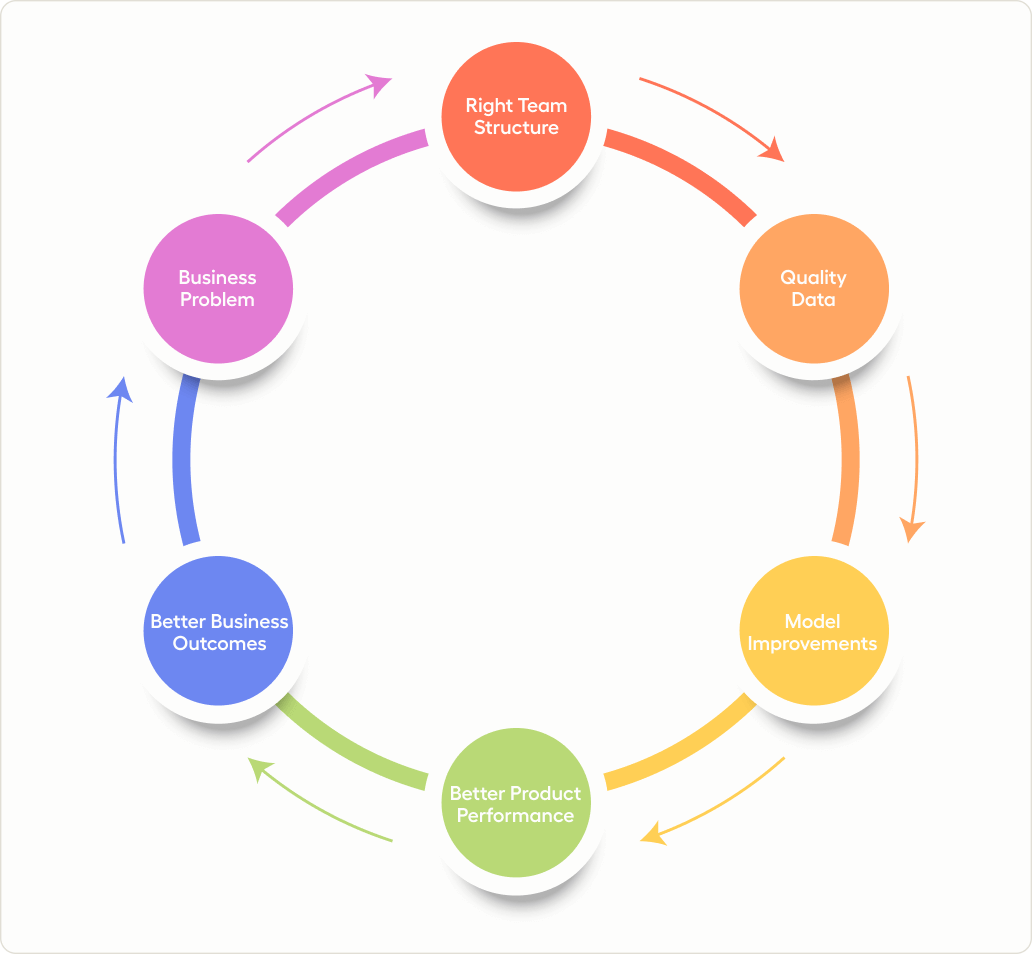
As you consider building a successful data annotation team, it's important to understand the concept of a virtuous cycle.
At its core, this virtuous cycle involves defining a business problem, creating the right team structure for addressing those problems, and collecting good data. By following this three-step process, you can improve your ML models and product performance, leading to better business outcomes.
But the virtuous cycle doesn't end there. As your company continues to enhance its products and services, expect to encounter new business problems. For example, you may uncover areas for improving customer satisfaction or discover opportunities to expand your offerings.
By embracing this virtuous cycle, you can achieve sustainable growth and success. Instead of relying on a quick fix or a one-time solution, you can establish a continuous process of improvement that leads to long-term success.