How Data Discovery Helps You Save Time and Improve Model Performance

Nate Kartchner
Director of Marketing
Director of Marketing
This is a summary of our recent livestream Save Time and Improve Model Performance with Data Discovery.
When we think about what the Label Studio platform is designed to do, we divide it into three different pillars: Discovery, Signal, and Supervise. Many of Label Studio’s features focus on automating labeling and providing streamlined workflows for annotators to provide human signal to the process (Signal); and providing data science teams with reports and analytics to monitor model and annotator performance, and data quality (Supervise). With the release of Data Discovery, we now have a much more powerful way of helping users connect structured and unstructured data sources to Label Studio and make that data searchable using natural language (Discovery).
We recently held a livestream where we demonstrated this new feature, and this blog post summarizes some of the content from that livestream. If you’d like to watch the stream in its entirety, you can watch it here.
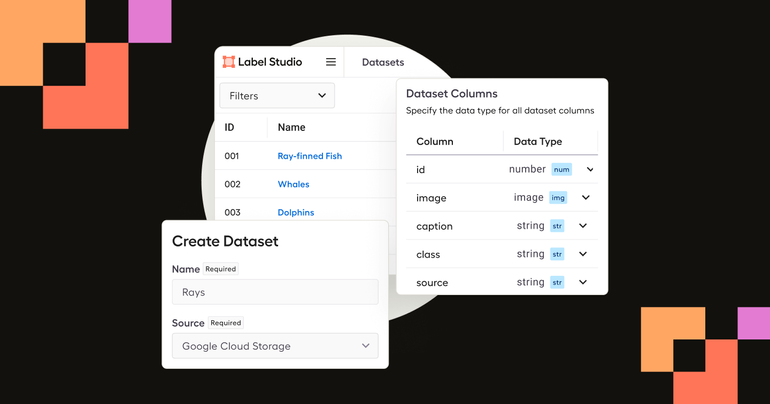
Data discovery stands as a crucial preliminary step in the data labeling process. It's not just about tagging data or marking boundaries; it starts much earlier. It involves organizing, identifying, understanding, and contextualizing data before it even reaches the labeling stage. This approach ensures a more holistic view of data management, offering a clearer pathway to the most effective use of the data. For most organizations, this process is extremely time-intensive and manual. It generally takes the form of notebook-based workflows tying together tools, workflows, and domain knowledge.
We have identified three major challenges that organizations are trying to solve:
We’ve designed Data Discovery with these challenges in mind.
To get a more concrete sense for how Data Discovery works in practice, let’s look at how one of our customers uses this new feature. So ACME, Inc. (not their real name) uses image data to assist farmers in identifying issues like crop health, water saturation, and pests. To do this, they are developing specific models for each crop type. To do this, the company analyzes thousands of field images to accurately identify crops and potential issues, such as weeds.
Previous to using Data Discovery, they would collect thousands of images from farmers. Then, one by one, they would go through the images to determine which ones were worth labeling. In many ways, it was almost like double-labeling to do the initial data-cleaning path to determine what was worth labeling before actually starting their labeling workflow.
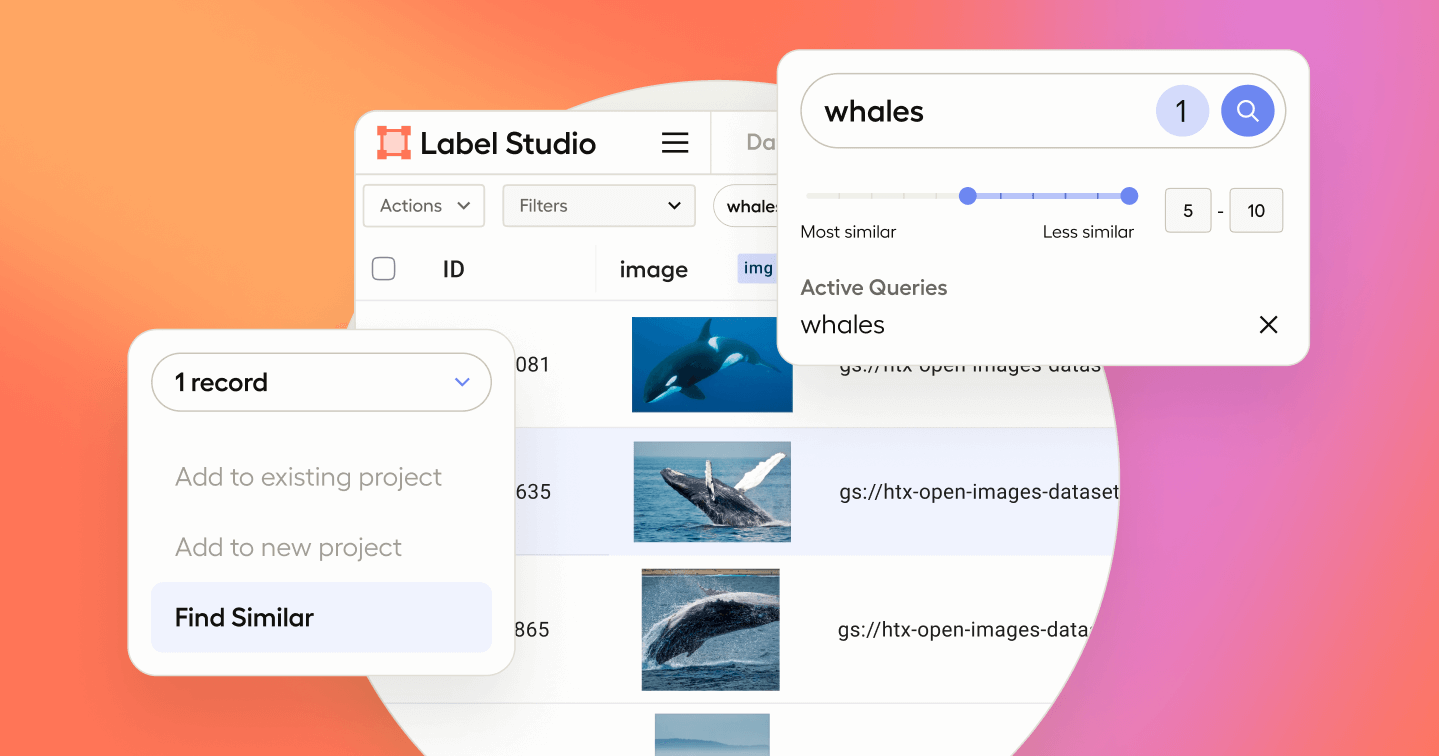
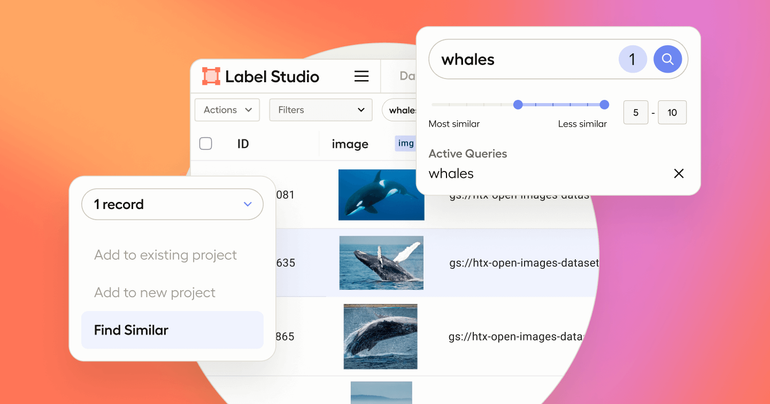
But since implementing Data Discovery, now they can just add these thousands of images into the platform and use natural language keyword searches and similarity search to focus in on the exact data items that they want to label. For example, say that their cabbage model is underperforming. They can now ask Data Discovery to find them a few cabbage pictures, ask the platform to find similar images, and then send them all to a manual labeling workflow in just a few minutes instead of hours or days.
If you want to see Data Discovery in action, check out the rest of the livestream - you can see just how easy it is to search through a massive and varied dataset to zero in on a specific set of items using similarity search and natural language search. If you’re interested in learning more about Data Discovery, you can request a demo here. Data Discovery is currently in beta and free to Label Studio Enterprise customers.
We’re delivering a new data discovery capability that allows users to easily index their cloud-scale datasets, search them with natural language and similarity, and provide seamless integration with Label Studio projects.

VP of Engineering
Announcing the beta release of Data Discovery, a data exploration and discovery interface built on our data labeling platform that helps teams visualize, identify, and operationalize unstructured data through automatic embedding generation and vector-based search.

Senior Product Marketing Manager

Harness Generative AI and ML models for pre-labeling, interactive labeling, and model evaluation.
