Now in Beta: Identify and Label Your Best Unstructured Data with Data Discovery

Sean Lynch
Senior Product Marketing Manager
Senior Product Marketing Manager
The adage “garbage in, garbage out” is a bit cliché these days, but still as true as ever. When we hear this term, we often think of data quality, usually label quality, to be more specific. But, the relevance and composition of the data you use for model training can have just as much impact on performance.
However, we’ve heard from our customers that finding the most relevant data from large unstructured datasets is a significant pain point and bottleneck for teams trying to build the next great ML or AI application. This led the HumanSignal team to build Data Discovery, which we released in a private preview earlier this year. Data Discovery is a data exploration and discovery interface built on our data labeling platform that helps teams visualize, identify, and operationalize unstructured data through automatic embedding generation and vector-based search. In its essence, it is a tool designed to unearth the hidden gems within your data.
Data Discovery addresses four fundamental challenges:
With Data Discovery, these hurdles can be surmounted without point solutions or coding. By centralizing and streamlining more of your data preparation workflows, specifically data sourcing and labeling, Data Discovery significantly increases dataset development and iteration velocity.
Today, I’m excited to announce that Data Discovery is now available to all enterprise customers as an open beta!
Companies collect more data than ever before. Far surpassing what most people could have envisioned a mere decade ago. Most get relegated to data lakes or cloud repositories. Left untouched, or sometimes forgotten, until necessity demands, often due to the costs associated with labeling. Many soon find themselves struggling to manage these mountains of data. What is relevant, and how do I find it? Extracting even a thousand pertinent examples for a specific project can prove daunting.
This challenge is compounded when the data lacks metadata or other identifiers, transforming the task into an exhaustive search through an overwhelming sea of noise.
Complicating matters further, the nature of the data itself often presents a labyrinth of complexity. Consider the realm of computer vision, where variables such as lighting conditions, perspective, and occlusions are but a few of the myriad factors at play that influence the data's relevance and quality. This makes visual inspection difficult, presupposing one has the luxury of ample time to undertake such an endeavor.
Manual sifting not only demands a significant investment of time but also increases the risk of overlooking valuable data ripe for labeling.
Data Discovery was built from the ground up to solve these issues - to make good and relevant data easy to find. So, what precisely is Data Discovery?
Data Discovery is an interface that helps teams explore and search unstructured data to find examples to label or use for fine-tuning. It generates embeddings for the data you connect and uses vector-based databases with reference embeddings to enable you to query that data using natural language or similarity. Once you've found what you need, you can send that data in seconds as a labeling task to a new or existing project. All of this within Label Studio itself.
The applications of Data Discovery span a broad spectrum:
In summary, Data Discovery is an invaluable tool for curating the most appropriate image or text dataset for your model. It helps you better understand the composition and quality of your datasets, while allowing you to find and zoom in on any problem areas. Perfectly compatible with active learning workflows and other systematic approaches to data selection, Data Discovery is a pivotal asset in pinpointing and prioritizing data that will most significantly enhance your model's performance, helping to distinguish the data that matters most from data that doesn't.
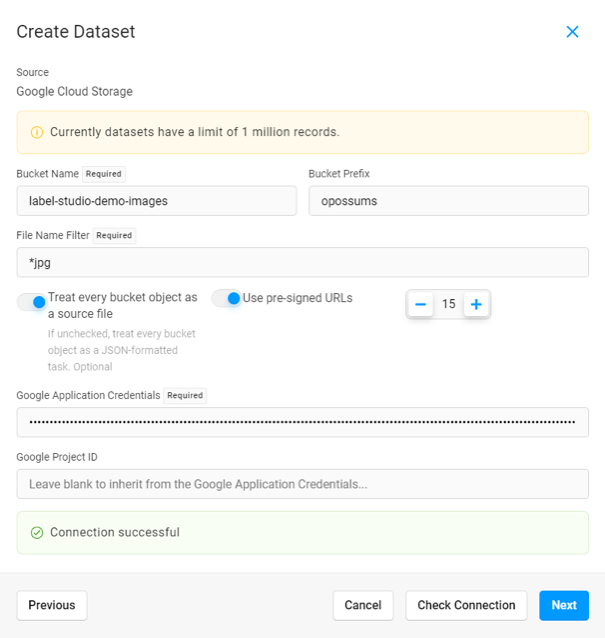
Create a dataset by connecting your Google Cloud, AWS S3, or Azure Blob cloud environment and importing your data. Data Discovery supports image and text data in .txt, .png, and .jpg/.jpeg formats, but additional data and file types will be supported in the future.
Embeddings are automatically generated to index and bring context to your unstructured data. They help represent complex data in a simpler format, and are used to convey meaning and measure similarity between data points in a way that things like keywords and metadata do not. This generation also occurs anytime you sync a dataset to account for any changes in your data that may impact these relationships.
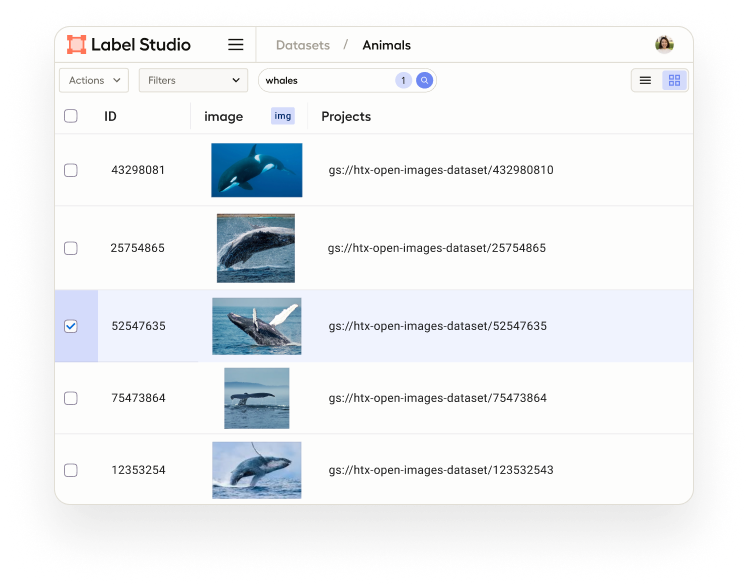
Get a visual snapshot of your data to better understand composition, quality, and other factors that performance metrics alone might not show. The grid view is useful for exploring and inspecting your dataset, or subsets of your dataset, particularly when combined with search. Or, switch to the list view for more detailed information on your data’s attributes. Adjustable columns and filters allow you to view more or less information as needed.

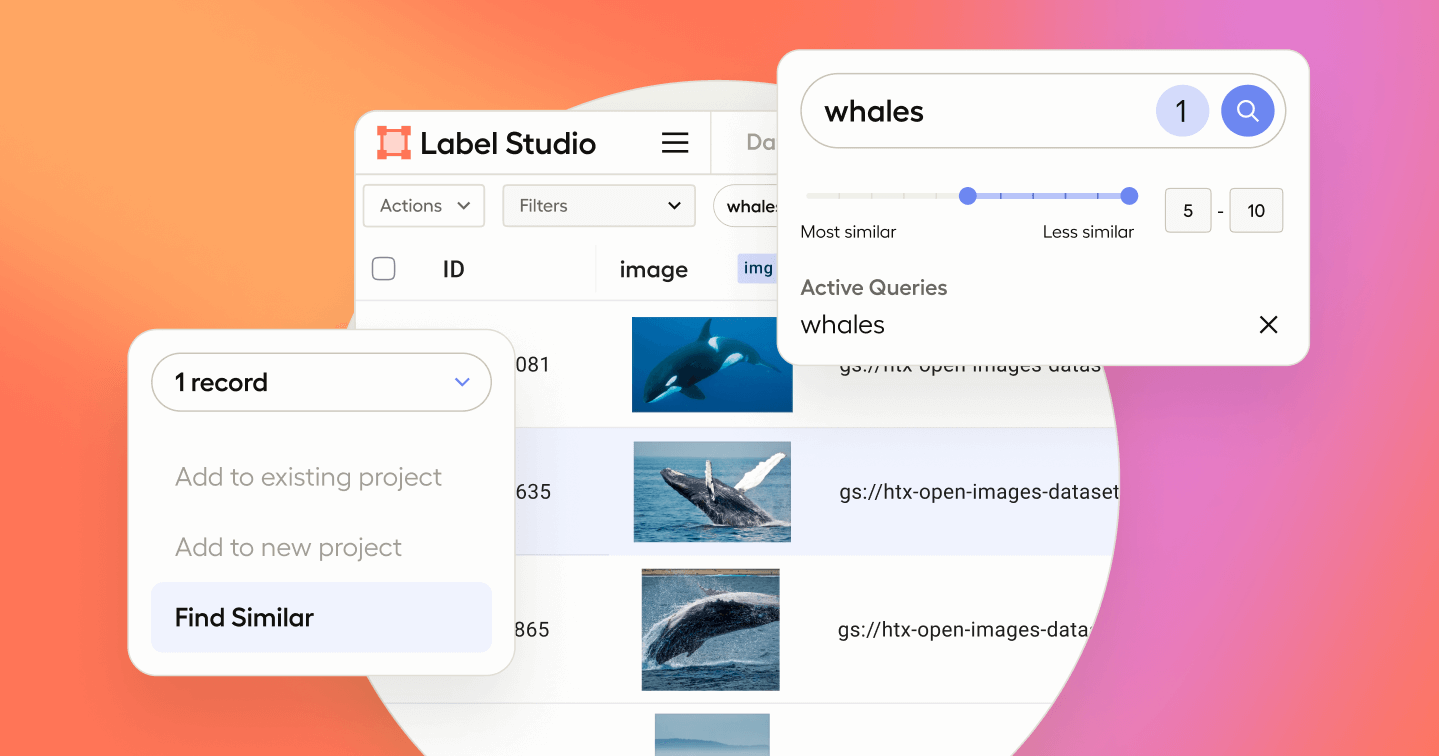
Quickly find data matching your desired conditions using natural language queries, also known as “semantic search.” This allows you to use one or more text-based keywords and phrases to uncover data. You can add more search queries to your original query to refine your search further.
Simply choose one or more reference images, and Data Discovery will sort your data based on their semantic similarity to your selections. You can further adjust your search by selecting or deselecting additional records. Both search forms can be combined to drill deep into your data for more complex and highly specific tasks.
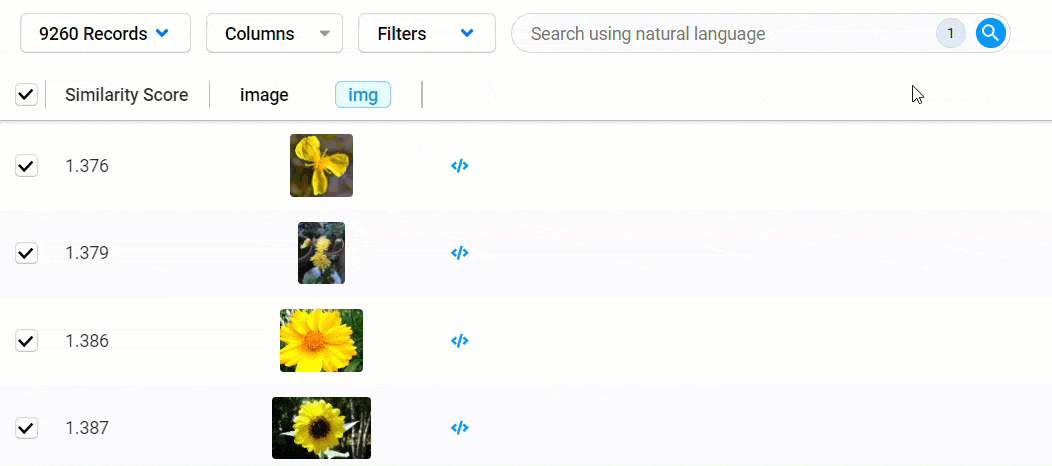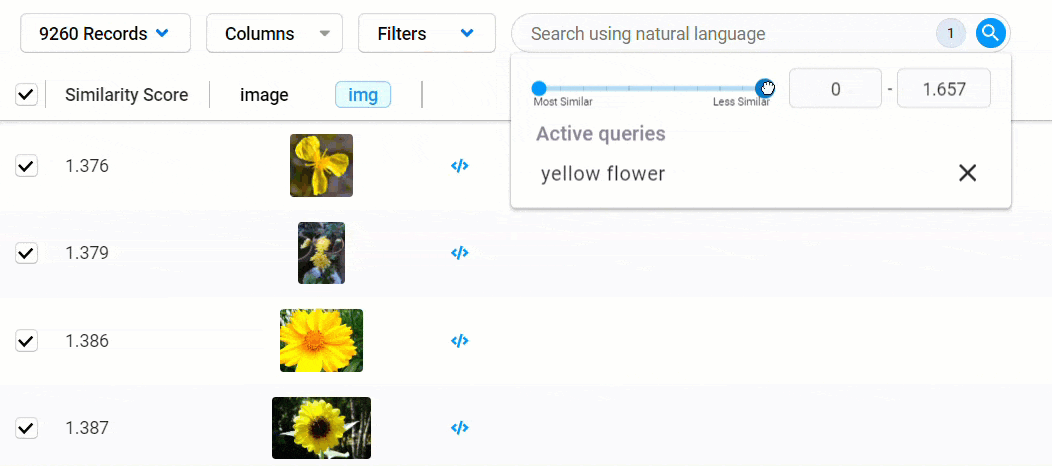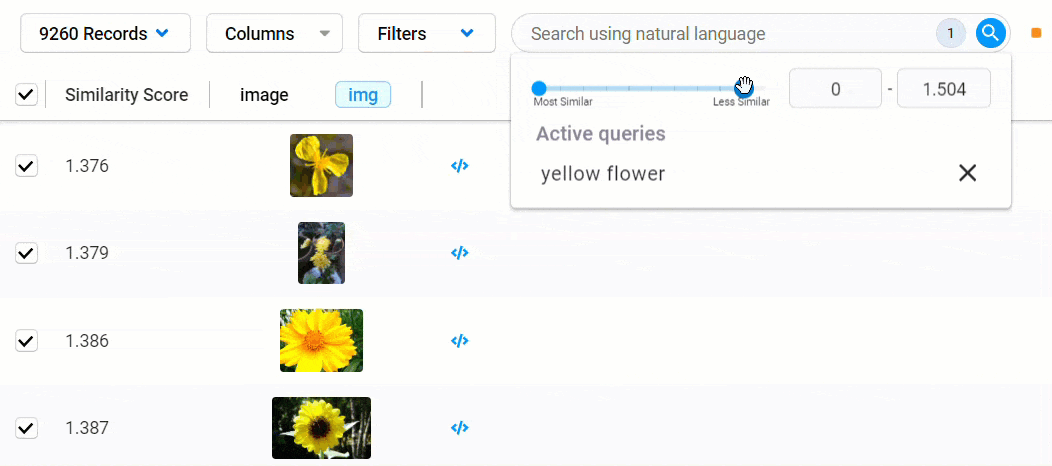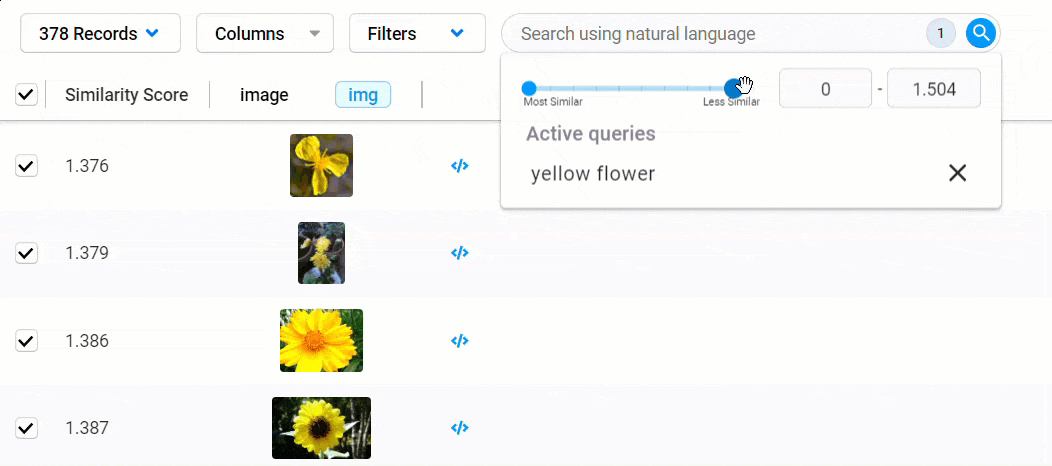
Remember those reference embeddings we mentioned earlier? Those are compared to the embeddings generated from each record in the dataset to calculate the distance between points, giving us a similarity score. The closer a score is to 0, the less distance between points and the more likely they match your search criteria.
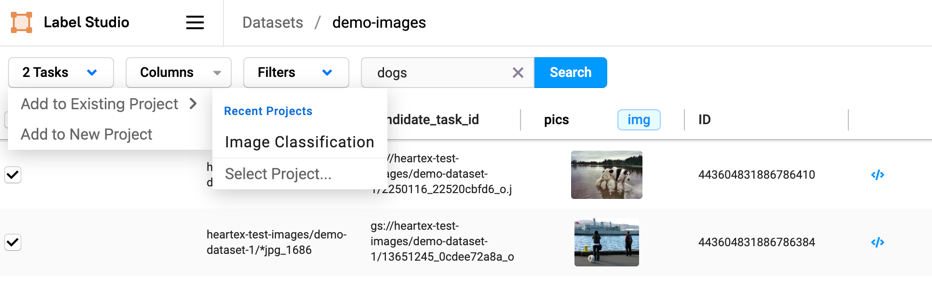
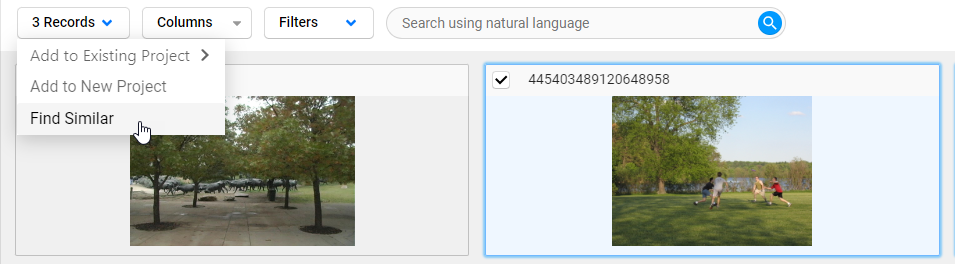
Create desired data subsets using the above search methods combined with filtering. Select meaningful data and seamlessly add this data to new or existing Label Studio Enterprise projects for labeling or review.
Getting started is super easy! If you’re a current Enterprise customer, all you need to do is reach out to your simply reach out to your customer success manager, or email cs@humansignal.com. You’ll receive a personalized onboarding and walkthrough, along with any additional assistance you may need as you get going with the beta.
Not yet a customer? We’d be happy to give you a personalized demo of Data Discovery, and show you how Label Studio Enterprise can help you tackle all your toughest data-related challenges at speed and scale. Plus, if you become a customer while Data Discovery is in beta, you can get exclusive free access to this new and exciting feature.
Your input during this beta phase is invaluable. We're wholeheartedly committed to refining Data Discovery, and your insights are vital in this process. We encourage you to share your experiences, offer suggestions for improvement, and express your desires for future features. Together, we're not just navigating new territory; we're shaping the future of data discovery and management.
Your feedback is the cornerstone of this endeavor, and we eagerly anticipate the collective progress we will achieve!

Harness Generative AI and ML models for pre-labeling, interactive labeling, and model evaluation.

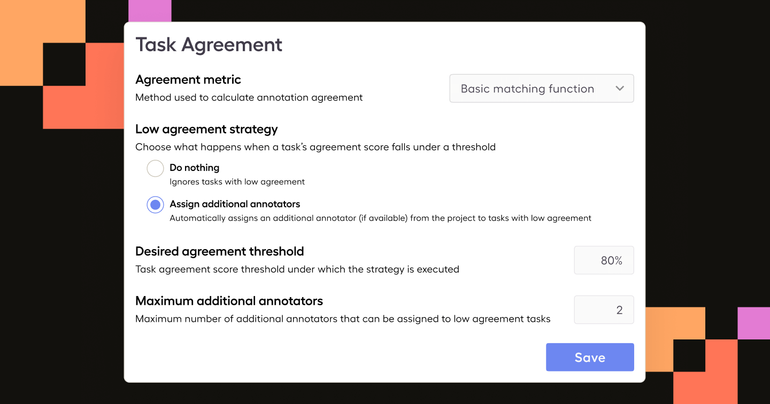
Today we’re launching a new feature to get your most challenging tasks in front of additional annotators—automatically.
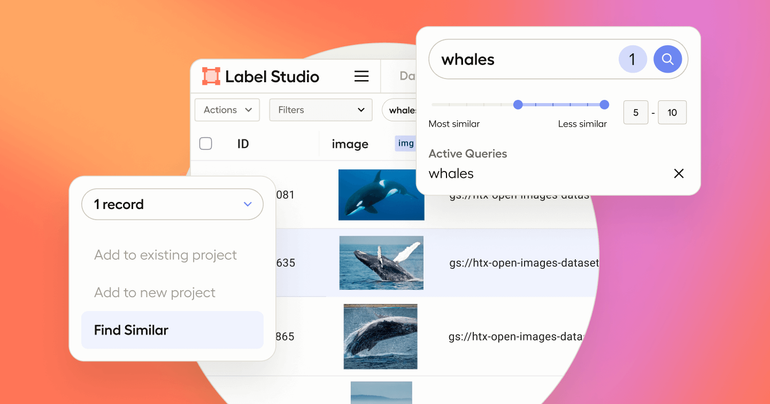
Data Discovery is designed to connect structured and unstructured data sources to Label Studio and make that data searchable using natural language. This is a summary of a recent livestream where we demonstrated this feature live and shared a case study.

Director of Marketing